
Multivariate normal distribution facts for kids
| Probability multivariate function MultivariateNormal.png |
|
| Cumulative distribution function |
|
| Parameters | μ ∈ Rk — location Σ ∈ Rk × k — covariance (positive semi-definite matrix) |
|---|---|
| Support | x ∈ μ + span(Σ) ⊆ Rk |
| Template:Probability distribution/link multivariate | 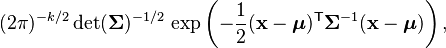 exists only when Σ is positive-definite |
| Cumulative distribution function (cdf) | {{{cdf}}} |
| Mean | μ |
| Median | |
| Mode | μ |
| Variance | Σ |
| Skewness | |
| Excess kurtosis | |
| Entropy | Failed to parse (PNG conversion failed; check for correct installation of latex and dvipng (or dvips + gs + convert)): \frac{1}{2} \ln \det\mathord\left( 2\pi \mathrm{e}\boldsymbol\Sigma \right) |
| Moment-generating function (mgf) | 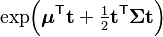 |
| Characteristic function | 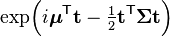 |
In probability theory and statistics, the multivariate normal distribution, multivariate Gaussian distribution, or joint normal distribution is a generalization of the one-dimensional (univariate) normal distribution to higher dimensions. One definition is that a random vector is said to be k-variate normally distributed if every linear combination of its k components has a univariate normal distribution. Its importance derives mainly from the multivariate central limit theorem. The multivariate normal distribution is often used to describe, at least approximately, any set of (possibly) correlated real-valued random variables each of which clusters around a mean value.
Contents
- Definitions
- Properties
- Statistical inference
- Computational methods
- See also
Definitions
Notation and parameterization
The multivariate normal distribution of a k-dimensional random vector 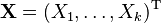 can be written in the following notation:
can be written in the following notation:
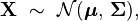
or to make it explicitly known that X is k-dimensional,
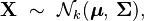
with k-dimensional mean vector
![\boldsymbol\mu = \operatorname{E}[\mathbf{X}] = ( \operatorname{E}[X_1], \operatorname{E}[X_2], \ldots, \operatorname{E}[X_k] ) ^ \textbf{T},](/images/math/4/3/4/434a9d6d11f241782be17cdb33684512.png)
and 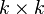 covariance matrix
covariance matrix
![\Sigma_{i,j} = \operatorname{E} [(X_i - \mu_i)( X_j - \mu_j)] = \operatorname{Cov}[X_i, X_j]](/images/math/f/4/e/f4eef49d90c064e851c3d90798e67fd9.png)
such that 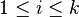 and
and 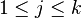 . The inverse of the covariance matrix is called the precision matrix, denoted by
. The inverse of the covariance matrix is called the precision matrix, denoted by  .
.
Standard normal random vector
A real random vector is called a standard normal random vector if all of its components 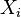 are independent and each is a zero-mean unit-variance normally distributed random variable, i.e. if
are independent and each is a zero-mean unit-variance normally distributed random variable, i.e. if 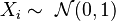 for all
for all  .
.
Centered normal random vector
A real random vector is called a centered normal random vector if there exists a deterministic 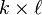 matrix
matrix 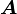 such that
such that 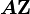 has the same distribution as
has the same distribution as 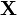 where
where 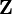 is a standard normal random vector with
is a standard normal random vector with 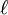 components.
components.
Normal random vector
A real random vector is called a normal random vector if there exists a random -vector , which is a standard normal random vector, a 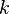 -vector
-vector 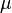 , and a matrix , such that
, and a matrix , such that 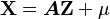 .
.
Formally:
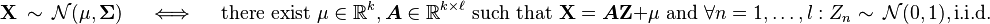
Here the covariance matrix is  .
.
In the degenerate case where the covariance matrix is singular, the corresponding distribution has no density; see the section below for details. This case arises frequently in statistics; for example, in the distribution of the vector of residuals in the ordinary least squares regression. The are in general not independent; they can be seen as the result of applying the matrix to a collection of independent Gaussian variables .
Equivalent definitions
The following definitions are equivalent to the definition given above. A random vector  has a multivariate normal distribution if it satisfies one of the following equivalent conditions.
has a multivariate normal distribution if it satisfies one of the following equivalent conditions.
- Every linear combination
 of its components is normally distributed. That is, for any constant vector
of its components is normally distributed. That is, for any constant vector  , the random variable
, the random variable  has a univariate normal distribution, where a univariate normal distribution with zero variance is a point mass on its mean.
has a univariate normal distribution, where a univariate normal distribution with zero variance is a point mass on its mean. - There is a k-vector and a symmetric, positive semidefinite matrix
 , such that the characteristic function of is
, such that the characteristic function of is 
The spherical normal distribution can be characterised as the unique distribution where components are independent in any orthogonal coordinate system.
Density function

Non-degenerate case
The multivariate normal distribution is said to be "non-degenerate" when the symmetric covariance matrix is positive definite. In this case the distribution has density
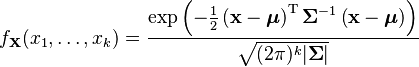
where 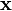 is a real k-dimensional column vector and
is a real k-dimensional column vector and  is the determinant of , also known as the generalized variance. The equation above reduces to that of the univariate normal distribution if is a
is the determinant of , also known as the generalized variance. The equation above reduces to that of the univariate normal distribution if is a 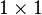 matrix (i.e. a single real number).
matrix (i.e. a single real number).
The circularly symmetric version of the complex normal distribution has a slightly different form.
Each iso-density locus — the locus of points in k-dimensional space each of which gives the same particular value of the density — is an ellipse or its higher-dimensional generalization; hence the multivariate normal is a special case of the elliptical distributions.
The quantity 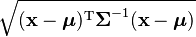 is known as the Mahalanobis distance, which represents the distance of the test point from the mean
is known as the Mahalanobis distance, which represents the distance of the test point from the mean 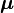 . Note that in the case when
. Note that in the case when  , the distribution reduces to a univariate normal distribution and the Mahalanobis distance reduces to the absolute value of the standard score. See also Interval below.
, the distribution reduces to a univariate normal distribution and the Mahalanobis distance reduces to the absolute value of the standard score. See also Interval below.
Bivariate case
In the 2-dimensional nonsingular case (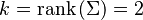 ), the probability density function of a vector Failed to parse (lexing error): \text{[XY]′} is:
), the probability density function of a vector Failed to parse (lexing error): \text{[XY]′} is: ![{\displaystyle
f(x,y) =
\frac{1}{2 \pi \sigma_X \sigma_Y \sqrt{1-\rho^2}}
\exp
\left( -\frac{1}{2\left[1 - \rho^2\right]}\left[
\left(\frac{x-\mu_X}{\sigma_X}\right)^2 -
2\rho\left(\frac{x - \mu_X}{\sigma_X}\right)\left(\frac{y - \mu_Y}{\sigma_Y}\right) +
\left(\frac{y - \mu_Y}{\sigma_Y}\right)^2
\right]
\right)
}](/images/math/1/0/7/1079776082526296417525cbca69a6aa.png) where
where 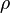 is the correlation between
is the correlation between 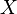 and
and 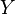 and where
and where 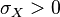 and
and 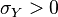 . In this case,
. In this case,
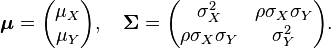
In the bivariate case, the first equivalent condition for multivariate reconstruction of normality can be made less restrictive as it is sufficient to verify that countably many distinct linear combinations of and are normal in order to conclude that the vector of Failed to parse (lexing error): \text{[XY]′} is bivariate normal.
The bivariate iso-density loci plotted in the 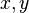 -plane are ellipses, whose principal axes are defined by the eigenvectors of the covariance matrix (the major and minor semidiameters of the ellipse equal the square-root of the ordered eigenvalues).
-plane are ellipses, whose principal axes are defined by the eigenvectors of the covariance matrix (the major and minor semidiameters of the ellipse equal the square-root of the ordered eigenvalues).

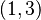 with a standard deviation of 3 in roughly the
with a standard deviation of 3 in roughly the  direction and of 1 in the orthogonal direction.
direction and of 1 in the orthogonal direction.As the absolute value of the correlation parameter increases, these loci are squeezed toward the following line :
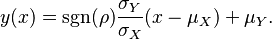
This is because this expression, with 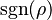 (where sgn is the Sign function) replaced by , is the best linear unbiased prediction of given a value of .
(where sgn is the Sign function) replaced by , is the best linear unbiased prediction of given a value of .
Degenerate case
If the covariance matrix is not full rank, then the multivariate normal distribution is degenerate and does not have a density. More precisely, it does not have a density with respect to k-dimensional Lebesgue measure (which is the usual measure assumed in calculus-level probability courses). Only random vectors whose distributions are absolutely continuous with respect to a measure are said to have densities (with respect to that measure). To talk about densities but avoid dealing with measure-theoretic complications it can be simpler to restrict attention to a subset of 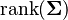 of the coordinates of
of the coordinates of 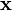 such that the covariance matrix for this subset is positive definite; then the other coordinates may be thought of as an affine function of these selected coordinates.
such that the covariance matrix for this subset is positive definite; then the other coordinates may be thought of as an affine function of these selected coordinates.
To talk about densities meaningfully in singular cases, then, we must select a different base measure. Using the disintegration theorem we can define a restriction of Lebesgue measure to the -dimensional affine subspace of 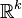 where the Gaussian distribution is supported, i.e.
where the Gaussian distribution is supported, i.e. 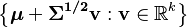 . With respect to this measure the distribution has the density of the following motif:
. With respect to this measure the distribution has the density of the following motif:
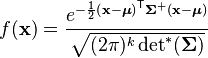
where 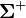 is the generalized inverse, is the rank of and
is the generalized inverse, is the rank of and 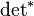 is the pseudo-determinant.
is the pseudo-determinant.
Cumulative distribution function
The notion of cumulative distribution function (cdf) in dimension 1 can be extended in two ways to the multidimensional case, based on rectangular and ellipsoidal regions.
The first way is to define the cdf 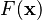 of a random vector as the probability that all components of are less than or equal to the corresponding values in the vector :
of a random vector as the probability that all components of are less than or equal to the corresponding values in the vector :

Though there is no closed form for , there are a number of algorithms that estimate it numerically.
Another way is to define the cdf 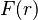 as the probability that a sample lies inside the ellipsoid determined by its Mahalanobis distance
as the probability that a sample lies inside the ellipsoid determined by its Mahalanobis distance  from the Gaussian, a direct generalization of the standard deviation. In order to compute the values of this function, closed analytic formulae exist, as follows.
from the Gaussian, a direct generalization of the standard deviation. In order to compute the values of this function, closed analytic formulae exist, as follows.
Interval
The interval for the multivariate normal distribution yields a region consisting of those vectors x satisfying
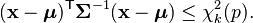
Here is a -dimensional vector, is the known -dimensional mean vector, is the known covariance matrix and 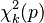 is the quantile function for probability
is the quantile function for probability 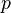 of the chi-squared distribution with degrees of freedom. When
of the chi-squared distribution with degrees of freedom. When  the expression defines the interior of an ellipse and the chi-squared distribution simplifies to an exponential distribution with mean equal to two (rate equal to half).
the expression defines the interior of an ellipse and the chi-squared distribution simplifies to an exponential distribution with mean equal to two (rate equal to half).
Complementary cumulative distribution function (tail distribution)
The complementary cumulative distribution function (ccdf) or the tail distribution is defined as  . When
. When 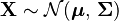 , then the ccdf can be written as a probability the maximum of dependent Gaussian variables:
, then the ccdf can be written as a probability the maximum of dependent Gaussian variables:
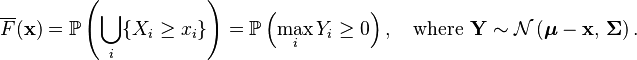
While no simple closed formula exists for computing the ccdf, the maximum of dependent Gaussian variables can be estimated accurately via the Monte Carlo method.
Properties
Probability in different domains

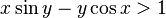 (blue regions). Middle: the probability of a trivariate normal in a toroidal domain. Bottom: converging Monte-Carlo integral of the probability of a 4-variate normal in the 4d regular polyhedral domain defined by
(blue regions). Middle: the probability of a trivariate normal in a toroidal domain. Bottom: converging Monte-Carlo integral of the probability of a 4-variate normal in the 4d regular polyhedral domain defined by 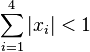 . These are all computed by the numerical method of ray-tracing.
. These are all computed by the numerical method of ray-tracing.The probability content of the multivariate normal in a quadratic domain defined by 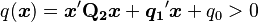 (where
(where 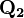 is a matrix,
is a matrix, 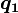 is a vector, and
is a vector, and 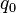 is a scalar), which is relevant for Bayesian classification/decision theory using Gaussian discriminant analysis, is given by the generalized chi-squared distribution. The probability content within any general domain defined by
is a scalar), which is relevant for Bayesian classification/decision theory using Gaussian discriminant analysis, is given by the generalized chi-squared distribution. The probability content within any general domain defined by 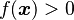 (where
(where 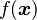 is a general function) can be computed using the numerical method of ray-tracing (Matlab code).
is a general function) can be computed using the numerical method of ray-tracing (Matlab code).
Higher moments
The kth-order moments of x are given by
![\mu_{1,\ldots,N}(\mathbf{x})
\mathrel\stackrel{\mathrm{def}}{=} \mu _{r_1,\ldots,r_N}(\mathbf{x})
\mathrel\stackrel{\mathrm{def}}{=} \operatorname E\left[ \prod_{j=1}^N X_j^{r_j} \right]](/images/math/1/e/3/1e39f84e99cc70ddc7ec6aff489aa330.png)
where r1 + r2 + ⋯ + rN = k.
The kth-order central moments are as follows
- If k is odd, μ1, …, N(x − μ) = 0.
- If k is even with k = 2λ, then

where the sum is taken over all allocations of the set  into λ (unordered) pairs. That is, for a kth (= 2λ = 6) central moment, one sums the products of λ = 3 covariances (the expected value μ is taken to be 0 in the interests of parsimony):
into λ (unordered) pairs. That is, for a kth (= 2λ = 6) central moment, one sums the products of λ = 3 covariances (the expected value μ is taken to be 0 in the interests of parsimony):
![\begin{align}
& \operatorname E[X_1 X_2 X_3 X_4 X_5 X_6] \\[8pt]
= {} & \operatorname E[X_1 X_2]\operatorname E[X_3 X_4]\operatorname E[X_5 X_6] + \operatorname E[X_1 X_2]\operatorname E[X_3 X_5]\operatorname E[X_4 X_6] + \operatorname E[X_1 X_2]\operatorname E[X_3 X_6] \operatorname E[X_4 X_5] \\[4pt]
& {} + \operatorname E[X_1 X_3]\operatorname E[X_2 X_4]\operatorname E[X_5 X_6] + \operatorname E[X_1 X_3]\operatorname E[X_2 X_5]\operatorname E[X_4 X_6] + \operatorname E[X_1 X_3]\operatorname E[X_2 X_6] \operatorname E[X_4 X_5] \\[4pt]
& {} + \operatorname E[X_1 X_4]\operatorname E[X_2 X_3]\operatorname E[X_5 X_6] + \operatorname E[X_1 X_4]\operatorname E[X_2 X_5]\operatorname E[X_3 X_6]+ \operatorname E[X_1 X_4]\operatorname E[X_2 X_6] \operatorname E[X_3 X_5] \\[4pt]
& {} + \operatorname E[X_1 X_5]\operatorname E[X_2 X_3]\operatorname E[X_4 X_6] + \operatorname E[X_1 X_5]\operatorname E[X_2 X_4]\operatorname E[X_3 X_6] + \operatorname E[X_1 X_5]\operatorname E[X_2 X_6] \operatorname E[X_3 X_4] \\[4pt]
& {} + \operatorname E[X_1 X_6]\operatorname E[X_2 X_3]\operatorname E[X_4 X_5] + \operatorname E[X_1 X_6]\operatorname E[X_2 X_4]\operatorname E[X_3 X_5] + \operatorname E[X_1 X_6] \operatorname E[X_2 X_5]\operatorname E[X_3 X_4].
\end{align}](/images/math/c/e/a/cea2df01085fc58dd2e8e724d34f7d17.png)
This yields 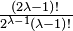 terms in the sum (15 in the above case), each being the product of λ (in this case 3) covariances. For fourth order moments (four variables) there are three terms. For sixth-order moments there are 3 × 5 = 15 terms, and for eighth-order moments there are 3 × 5 × 7 = 105 terms.
terms in the sum (15 in the above case), each being the product of λ (in this case 3) covariances. For fourth order moments (four variables) there are three terms. For sixth-order moments there are 3 × 5 = 15 terms, and for eighth-order moments there are 3 × 5 × 7 = 105 terms.
The covariances are then determined by replacing the terms of the list ![[ 1, \ldots, 2\lambda]](/images/math/5/8/e/58eb9de99c7aa0fbaf3ba34adcf6653e.png) by the corresponding terms of the list consisting of r1 ones, then r2 twos, etc.. To illustrate this, examine the following 4th-order central moment case:
by the corresponding terms of the list consisting of r1 ones, then r2 twos, etc.. To illustrate this, examine the following 4th-order central moment case:
![\begin{align}
\operatorname E \left [ X_i^4 \right ] & = 3\sigma_{ii}^2 \\[4pt]
\operatorname E \left[ X_i^3 X_j \right ] & = 3\sigma_{ii} \sigma_{ij} \\[4pt]
\operatorname E \left[ X_i^2 X_j^2 \right ] & = \sigma_{ii}\sigma_{jj}+2 \sigma _{ij}^2 \\[4pt]
\operatorname E \left[ X_i^2 X_j X_k \right ] & = \sigma_{ii}\sigma _{jk}+2\sigma _{ij}\sigma_{ik} \\[4pt]
\operatorname E \left [ X_i X_j X_k X_n \right ] & = \sigma_{ij}\sigma _{kn} + \sigma _{ik} \sigma_{jn} + \sigma_{in} \sigma _{jk}.
\end{align}](/images/math/4/c/2/4c2c870d12257be1686945b852f50480.png)
where 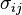 is the covariance of Xi and Xj. With the above method one first finds the general case for a kth moment with k different X variables,
is the covariance of Xi and Xj. With the above method one first finds the general case for a kth moment with k different X variables, ![E\left[ X_i X_j X_k X_n\right]](/images/math/c/f/7/cf7446bc0444c0d68bd8dd68dd68a195.png) , and then one simplifies this accordingly. For example, for
, and then one simplifies this accordingly. For example, for ![\operatorname E[ X_i^2 X_k X_n ]](/images/math/8/7/8/8784287779842ec2fdcc0e6aa8b9f913.png) , one lets Xi = Xj and one uses the fact that
, one lets Xi = Xj and one uses the fact that  .
.
Functions of a normal vector

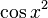 of a single normal variable
of a single normal variable 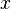 with
with  and
and  . b: Probability density of a function
. b: Probability density of a function 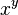 of a normal vector
of a normal vector 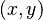 , with mean
, with mean 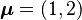 , and covariance
, and covariance 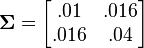 . c: Heat map of the joint probability density of two functions of a normal vector , with mean
. c: Heat map of the joint probability density of two functions of a normal vector , with mean 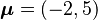 , and covariance
, and covariance 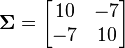 . d: Probability density of a function
. d: Probability density of a function 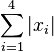 of 4 iid standard normal variables. These are computed by the numerical method of ray-tracing.
of 4 iid standard normal variables. These are computed by the numerical method of ray-tracing.A quadratic form of a normal vector 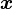 ,
,  (where is a matrix, is a vector, and is a scalar), is a generalized chi-squared variable.
(where is a matrix, is a vector, and is a scalar), is a generalized chi-squared variable.
If is a general scalar-valued function of a normal vector, its probability density function, cumulative distribution function, and inverse cumulative distribution function can be computed with the numerical method of ray-tracing (Matlab code).
Likelihood function
If the mean and covariance matrix are known, the log likelihood of an observed vector is simply the log of the probability density function:
![\ln L (\boldsymbol{x})= -\frac{1}{2} \left[ \ln (|\boldsymbol\Sigma|\,) + (\boldsymbol{x}-\boldsymbol\mu)'\boldsymbol\Sigma^{-1}(\boldsymbol{x}-\boldsymbol\mu) + k\ln(2\pi) \right]](/images/math/7/2/5/725babceb30a28fc5ca6e61246108a30.png) ,
,
The circularly symmetric version of the noncentral complex case, where 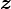 is a vector of complex numbers, would be
is a vector of complex numbers, would be

i.e. with the conjugate transpose (indicated by  ) replacing the normal transpose (indicated by
) replacing the normal transpose (indicated by  ). This is slightly different than in the real case, because the circularly symmetric version of the complex normal distribution has a slightly different form for the normalization constant.
). This is slightly different than in the real case, because the circularly symmetric version of the complex normal distribution has a slightly different form for the normalization constant.
A similar notation is used for multiple linear regression.
Since the log likelihood of a normal vector is a quadratic form of the normal vector, it is distributed as a generalized chi-squared variable.
Differential entropy
The differential entropy of the multivariate normal distribution is
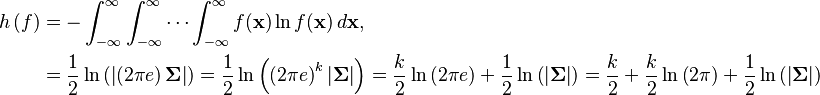
where the bars denote the matrix determinant and k is the dimensionality of the vector space.
Kullback–Leibler divergence
The Kullback–Leibler divergence from 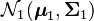 to
to 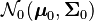 , for non-singular matrices Σ1 and Σ0, is:
, for non-singular matrices Σ1 and Σ0, is:
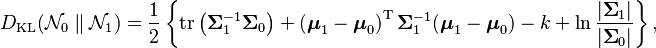
where is the dimension of the vector space.
The logarithm must be taken to base e since the two terms following the logarithm are themselves base-e logarithms of expressions that are either factors of the density function or otherwise arise naturally. The equation therefore gives a result measured in nats. Dividing the entire expression above by loge 2 yields the divergence in bits.
When  ,
,
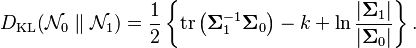
Mutual information
The mutual information of a distribution is a special case of the Kullback–Leibler divergence in which 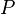 is the full multivariate distribution and
is the full multivariate distribution and 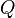 is the product of the 1-dimensional marginal distributions. In the notation of the Kullback–Leibler divergence section of this article,
is the product of the 1-dimensional marginal distributions. In the notation of the Kullback–Leibler divergence section of this article,  is a diagonal matrix with the diagonal entries of
is a diagonal matrix with the diagonal entries of  , and . The resulting formula for mutual information is:
, and . The resulting formula for mutual information is:

where 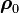 is the correlation matrix constructed from .
is the correlation matrix constructed from .
In the bivariate case the expression for the mutual information is:
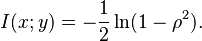
Joint normality
Normally distributed and independent
If and are normally distributed and independent, this implies they are "jointly normally distributed", i.e., the pair 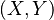 must have multivariate normal distribution. However, a pair of jointly normally distributed variables need not be independent (would only be so if uncorrelated,
must have multivariate normal distribution. However, a pair of jointly normally distributed variables need not be independent (would only be so if uncorrelated,  ).
).
Two normally distributed random variables need not be jointly bivariate normal
The fact that two random variables and both have a normal distribution does not imply that the pair has a joint normal distribution. A simple example is one in which X has a normal distribution with expected value 0 and variance 1, and  if
if 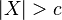 and
and  if
if 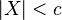 , where
, where 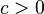 . There are similar counterexamples for more than two random variables. In general, they sum to a mixture model.
. There are similar counterexamples for more than two random variables. In general, they sum to a mixture model.
Correlations and independence
In general, random variables may be uncorrelated but statistically dependent. But if a random vector has a multivariate normal distribution then any two or more of its components that are uncorrelated are independent. This implies that any two or more of its components that are pairwise independent are independent. But, as pointed out just above, it is not true that two random variables that are (separately, marginally) normally distributed and uncorrelated are independent.
Conditional distributions
If N-dimensional x is partitioned as follows
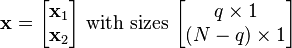
and accordingly μ and Σ are partitioned as follows
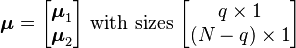
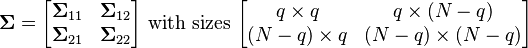
then the distribution of x1 conditional on x2 = a is multivariate normal (x1 | x2 = a) ~ N(μ, Σ) where
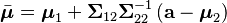
and covariance matrix

Here 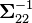 is the generalized inverse of
is the generalized inverse of  . The matrix
. The matrix 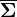 is the Schur complement of Σ22 in Σ. That is, the equation above is equivalent to inverting the overall covariance matrix, dropping the rows and columns corresponding to the variables being conditioned upon, and inverting back to get the conditional covariance matrix.
is the Schur complement of Σ22 in Σ. That is, the equation above is equivalent to inverting the overall covariance matrix, dropping the rows and columns corresponding to the variables being conditioned upon, and inverting back to get the conditional covariance matrix.
Note that knowing that x2 = a alters the variance, though the new variance does not depend on the specific value of a; perhaps more surprisingly, the mean is shifted by 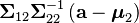 ; compare this with the situation of not knowing the value of a, in which case x1 would have distribution
; compare this with the situation of not knowing the value of a, in which case x1 would have distribution  .
.
An interesting fact derived in order to prove this result, is that the random vectors 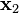 and
and 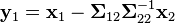 are independent.
are independent.
The matrix Σ12Σ22−1 is known as the matrix of regression coefficients.
Bivariate case
In the bivariate case where x is partitioned into 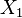 and
and 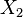 , the conditional distribution of given is
, the conditional distribution of given is
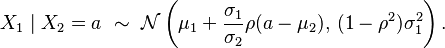
where is the correlation coefficient between and .
Bivariate conditional expectation
In the general case

The conditional expectation of X1 given X2 is:
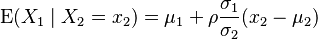
Proof: the result is obtained by taking the expectation of the conditional distribution  above.
above.
In the centered case with unit variances
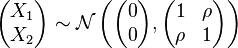
The conditional expectation of X1 given X2 is
and the conditional variance is
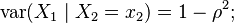
thus the conditional variance does not depend on x2.
The conditional expectation of X1 given that X2 is smaller/bigger than z is:
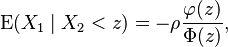
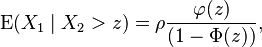
where the final ratio here is called the inverse Mills ratio.
Proof: the last two results are obtained using the result 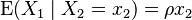 , so that
, so that
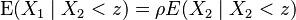 and then using the properties of the expectation of a truncated normal distribution.
and then using the properties of the expectation of a truncated normal distribution.
Marginal distributions
To obtain the marginal distribution over a subset of multivariate normal random variables, one only needs to drop the irrelevant variables (the variables that one wants to marginalize out) from the mean vector and the covariance matrix. The proof for this follows from the definitions of multivariate normal distributions and linear algebra.
Example
Let X = [X1, X2, X3] be multivariate normal random variables with mean vector μ = [μ1, μ2, μ3] and covariance matrix Σ (standard parametrization for multivariate normal distributions). Then the joint distribution of X′ = [X1, X3] is multivariate normal with mean vector μ′ = [μ1, μ3] and covariance matrix 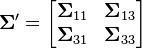 .
.
Affine transformation
If Y = c + BX is an affine transformation of 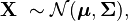 where c is an
where c is an 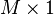 vector of constants and B is a constant
vector of constants and B is a constant  matrix, then Y has a multivariate normal distribution with expected value c + Bμ and variance BΣBT i.e.,
matrix, then Y has a multivariate normal distribution with expected value c + Bμ and variance BΣBT i.e.,  . In particular, any subset of the Xi has a marginal distribution that is also multivariate normal. To see this, consider the following example: to extract the subset (X1, X2, X4)T, use
. In particular, any subset of the Xi has a marginal distribution that is also multivariate normal. To see this, consider the following example: to extract the subset (X1, X2, X4)T, use
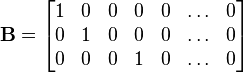
which extracts the desired elements directly.
Another corollary is that the distribution of Z = b · X, where b is a constant vector with the same number of elements as X and the dot indicates the dot product, is univariate Gaussian with 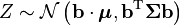 . This result follows by using
. This result follows by using
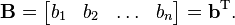
Observe how the positive-definiteness of Σ implies that the variance of the dot product must be positive.
An affine transformation of X such as 2X is not the same as the sum of two independent realisations of X.
Statistical inference
Parameter estimation
The derivation of the maximum-likelihood estimator of the covariance matrix of a multivariate normal distribution is straightforward.
In short, the probability density function (pdf) of a multivariate normal is
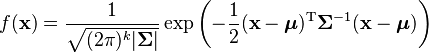
and the ML estimator of the covariance matrix from a sample of n observations is
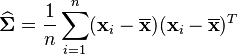
which is simply the sample covariance matrix. This is a biased estimator whose expectation is
![E\left[\widehat{\boldsymbol\Sigma}\right] = \frac{n-1}{n} \boldsymbol\Sigma.](/images/math/6/0/e/60e63ac0371cfd57d00f9b4943ff536f.png)
An unbiased sample covariance is
![\widehat{\boldsymbol\Sigma} = \frac1{n-1}\sum_{i=1}^n (\mathbf{x}_i-\overline{\mathbf{x}})(\mathbf{x}_i-\overline{\mathbf{x}})^{\rm T}
= \frac1{n-1} \left[X'\left(I - \frac{1}{n} \cdot J\right) X\right]](/images/math/d/8/5/d85328f11d5527ac3fee267f2a8bcbb1.png) (matrix form;
(matrix form; 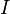 is the
is the 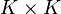 identity matrix, J is a matrix of ones; the term in parentheses is thus the centering matrix)
identity matrix, J is a matrix of ones; the term in parentheses is thus the centering matrix)
The Fisher information matrix for estimating the parameters of a multivariate normal distribution has a closed form expression. This can be used, for example, to compute the Cramér–Rao bound for parameter estimation in this setting. See Fisher information for more details.
Bayesian inference
In Bayesian statistics, the conjugate prior of the mean vector is another multivariate normal distribution, and the conjugate prior of the covariance matrix is an inverse-Wishart distribution 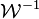 . Suppose then that n observations have been made
. Suppose then that n observations have been made
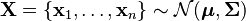
and that a conjugate prior has been assigned, where

where
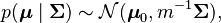
and
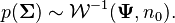
Then,

where

Multivariate normality tests
Multivariate normality tests check a given set of data for similarity to the multivariate normal distribution. The null hypothesis is that the data set is similar to the normal distribution, therefore a sufficiently small p-value indicates non-normal data. Multivariate normality tests include the Cox–Small test and Smith and Jain's adaptation of the Friedman–Rafsky test created by Larry Rafsky and Jerome Friedman.
Mardia's test is based on multivariate extensions of skewness and kurtosis measures. For a sample {x1, ..., xn} of k-dimensional vectors we compute
![\begin{align}
& \widehat{\boldsymbol\Sigma} = {1 \over n} \sum_{j=1}^n \left(\mathbf{x}_j - \bar{\mathbf{x}}\right)\left(\mathbf{x}_j - \bar{\mathbf{x}}\right)^\mathsf{T} \\
& A = {1 \over 6n} \sum_{i=1}^n \sum_{j=1}^n \left[ (\mathbf{x}_i - \bar{\mathbf{x}})^T\;\widehat{\boldsymbol\Sigma}^{-1} (\mathbf{x}_j - \bar{\mathbf{x}}) \right]^3 \\
& B = \sqrt{\frac{n}{8k(k+2)}}\left\{{1 \over n} \sum_{i=1}^n \left[ (\mathbf{x}_i - \bar{\mathbf{x}})^T\;\widehat{\boldsymbol\Sigma}^{-1} (\mathbf{x}_i - \bar{\mathbf{x}}) \right]^2 - k(k+2) \right\}
\end{align}](/images/math/b/b/c/bbc4c43454b0b9e7319e12a8c676bd6e.png)
Under the null hypothesis of multivariate normality, the statistic A will have approximately a chi-squared distribution with 16⋅k(k + 1)(k + 2) degrees of freedom, and B will be approximately standard normal N(0,1).
Mardia's kurtosis statistic is skewed and converges very slowly to the limiting normal distribution. For medium size samples 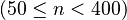 , the parameters of the asymptotic distribution of the kurtosis statistic are modified For small sample tests (
, the parameters of the asymptotic distribution of the kurtosis statistic are modified For small sample tests ( ) empirical critical values are used. Tables of critical values for both statistics are given by Rencher for k = 2, 3, 4.
) empirical critical values are used. Tables of critical values for both statistics are given by Rencher for k = 2, 3, 4.
Mardia's tests are affine invariant but not consistent. For example, the multivariate skewness test is not consistent against symmetric non-normal alternatives.
The BHEP test computes the norm of the difference between the empirical characteristic function and the theoretical characteristic function of the normal distribution. Calculation of the norm is performed in the L2(μ) space of square-integrable functions with respect to the Gaussian weighting function  . The test statistic is
. The test statistic is
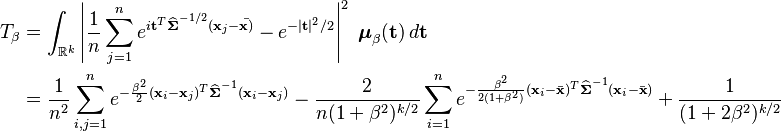
The limiting distribution of this test statistic is a weighted sum of chi-squared random variables, however in practice it is more convenient to compute the sample quantiles using the Monte-Carlo simulations.
A detailed survey of these and other test procedures is available.
Classification into multivariate normal classes

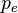 is the probability of total classification error. Right: the error matrix.
is the probability of total classification error. Right: the error matrix. 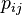 is the probability of classifying a sample from normal
is the probability of classifying a sample from normal 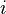 as
as 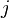 . These are computed by the numerical method of ray-tracing (Matlab code).
. These are computed by the numerical method of ray-tracing (Matlab code).Computational methods
Drawing values from the distribution
A widely used method for drawing (sampling) a random vector x from the N-dimensional multivariate normal distribution with mean vector μ and covariance matrix Σ works as follows:
- Find any real matrix A such that A AT = Σ. When Σ is positive-definite, the Cholesky decomposition is typically used, and the extended form of this decomposition can always be used (as the covariance matrix may be only positive semi-definite) in both cases a suitable matrix A is obtained. An alternative is to use the matrix A = UΛ½ obtained from a spectral decomposition Σ = UΛU−1 of Σ. The former approach is more computationally straightforward but the matrices A change for different orderings of the elements of the random vector, while the latter approach gives matrices that are related by simple re-orderings. In theory both approaches give equally good ways of determining a suitable matrix A, but there are differences in computation time.
- Let z = (z1, …, zN)T be a vector whose components are N independent standard normal variates (which can be generated, for example, by using the Box–Muller transform).
- Let x be μ + Az. This has the desired distribution due to the affine transformation property.
See also
 In Spanish: Distribución normal multivariada para niños
In Spanish: Distribución normal multivariada para niños
- Chi distribution, the pdf of the 2-norm (Euclidean norm or vector length) of a multivariate normally distributed vector (uncorrelated and zero centered).
- Rayleigh distribution, the pdf of the vector length of a bivariate normally distributed vector (uncorrelated and zero centered)
- Rice distribution, the pdf of the vector length of a bivariate normally distributed vector (uncorrelated and non-centered)
- Hoyt distribution, the pdf of the vector length of a bivariate normally distributed vector (correlated and centered)
- Complex normal distribution, an application of bivariate normal distribution
- Copula, for the definition of the Gaussian or normal copula model.
- Multivariate t-distribution, which is another widely used spherically symmetric multivariate distribution.
- Multivariate stable distribution extension of the multivariate normal distribution, when the index (exponent in the characteristic function) is between zero and two.
- Mahalanobis distance
- Wishart distribution
- Matrix normal distribution
