
DALL-E facts for kids

Watermark present on DALL·E images
|
|

An image generated by DALL·E 2, from the prompt "Teddy bears working on new AI research underwater with 1990s technology"
|
|
| Developer(s) | OpenAI |
|---|---|
| Initial release | 5 January 2021 |
| Stable release |
DALL·E 3 / 10 August 2023
|
| Type | Text-to-image model |
DALL·E, DALL·E 2, and DALL·E 3 are text-to-image models developed by OpenAI using deep learning methodologies to generate digital images from natural language descriptions known as "prompts".
The first version of DALL-E was announced in January 2021. In the following year, its successor DALL-E 2 was released. DALL·E 3 was released natively into ChatGPT for ChatGPT Plus and ChatGPT Enterprise customers in October 2023, with availability via OpenAI's API and "Labs" platform provided in early November. Microsoft implemented the model in Bing's Image Creator tool and plans to implement it into their Designer app.
Contents
History and background
DALL·E was revealed by OpenAI in a blog post on 5 January 2021, and uses a version of GPT-3 modified to generate images.
On 6 April 2022, OpenAI announced DALL·E 2, a successor designed to generate more realistic images at higher resolutions that "can combine concepts, attributes, and styles". On 20 July 2022, DALL·E 2 entered into a beta phase with invitations sent to 1 million waitlisted individuals; users could generate a certain number of images for free every month and may purchase more. Access had previously been restricted to pre-selected users for a research preview due to concerns about ethics and safety. On 28 September 2022, DALL·E 2 was opened to everyone and the waitlist requirement was removed. In September 2023, OpenAI announced their latest image model, DALL·E 3, capable of understanding "significantly more nuance and detail" than previous iterations. In early November 2022, OpenAI released DALL·E 2 as an API, allowing developers to integrate the model into their own applications. Microsoft unveiled their implementation of DALL·E 2 in their Designer app and Image Creator tool included in Bing and Microsoft Edge. The API operates on a cost-per-image basis, with prices varying depending on image resolution. Volume discounts are available to companies working with OpenAI's enterprise team.
The software's name is a portmanteau of the names of animated robot Pixar character WALL-E and the Catalan surrealist artist Salvador Dalí.
In February 2024, OpenAI began adding watermarks to DALL-E generated images, containing metadata in the C2PA (Coalition for Content Provenance and Authenticity) standard promoted by the Content Authenticity Initiative.
Technology
The first generative pre-trained transformer (GPT) model was initially developed by OpenAI in 2018, using a Transformer architecture. The first iteration, GPT-1, was scaled up to produce GPT-2 in 2019; in 2020, it was scaled up again to produce GPT-3, with 175 billion parameters.
DALL·E's model is a multimodal implementation of GPT-3 with 12 billion parameters which "swaps text for pixels," trained on text–image pairs from the Internet. In detail, the input to the Transformer model is a sequence of tokenized image caption followed by tokenized image patches. The image caption is in English, tokenized by byte pair encoding (vocabulary size 16384), and can be up to 256 tokens long. Each image is a 256×256 RGB image, divided into 32×32 patches of 4×4 each. Each patch is then converted by a discrete variational autoencoder to a token (vocabulary size 8192).
DALL·E was developed and announced to the public in conjunction with CLIP (Contrastive Language-Image Pre-training). CLIP is a separate model based on zero-shot learning that was trained on 400 million pairs of images with text captions scraped from the Internet. Its role is to "understand and rank" DALL·E's output by predicting which caption from a list of 32,768 captions randomly selected from the dataset (of which one was the correct answer) is most appropriate for an image. This model is used to filter a larger initial list of images generated by DALL·E to select the most appropriate outputs.
DALL·E 2 uses 3.5 billion parameters, a smaller number than its predecessor. DALL·E 2 uses a diffusion model conditioned on CLIP image embeddings, which, during inference, are generated from CLIP text embeddings by a prior model.
Contrastive Language-Image Pre-training (CLIP)
Contrastive Language-Image Pre-training is a technique for training a pair of models. One model takes in a piece of text and outputs a single vector. Another takes in an image and outputs a single vector.
To train such a pair of models, one would start by preparing a large dataset of image-caption pairs, then sample batches of size 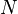 . Let the outputs from the text and image models be respectively
. Let the outputs from the text and image models be respectively 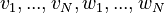 . The loss incurred on this batch is:
. The loss incurred on this batch is: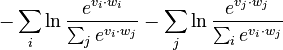 In words, it is the total sum of cross-entropy loss across every column and every row of the matrix
In words, it is the total sum of cross-entropy loss across every column and every row of the matrix ![[v_i \cdot w_j]_{i, j}](/images/math/1/f/0/1f0d33d177be7cced8d2c41f886f1b5a.png) .
.
The models released were trained on a dataset "WebImageText," containing 400 million pairs of image-captions. The total number of words is similar to WebText, which contains about 40 GB of text.
Capabilities
DALL·E can generate imagery in multiple styles, including photorealistic imagery, paintings, and emoji. It can "manipulate and rearrange" objects in its images, and can correctly place design elements in novel compositions without explicit instruction. Thom Dunn writing for BoingBoing remarked that "For example, when asked to draw a daikon radish blowing its nose, sipping a latte, or riding a unicycle, DALL·E often draws the handkerchief, hands, and feet in plausible locations." DALL·E showed the ability to "fill in the blanks" to infer appropriate details without specific prompts, such as adding Christmas imagery to prompts commonly associated with the celebration, and appropriately placed shadows to images that did not mention them. Furthermore, DALL·E exhibits a broad understanding of visual and design trends.
DALL·E can produce images for a wide variety of arbitrary descriptions from various viewpoints with only rare failures. Mark Riedl, an associate professor at the Georgia Tech School of Interactive Computing, found that DALL-E could blend concepts (described as a key element of human creativity).
Its visual reasoning ability is sufficient to solve Raven's Matrices (visual tests often administered to humans to measure intelligence).

DALL·E 3 follows complex prompts with more accuracy and detail than its predecessors, and is able to generate more coherent and accurate text. DALL·E 3 is integrated into ChatGPT Plus.
Image modification


Given an existing image, DALL·E 2 can produce "variations" of the image as individual outputs based on the original, as well as edit the image to modify or expand upon it. DALL·E 2's "inpainting" and "outpainting" use context from an image to fill in missing areas using a medium consistent with the original, following a given prompt.
For example, this can be used to insert a new subject into an image, or expand an image beyond its original borders. According to OpenAI, "Outpainting takes into account the image’s existing visual elements — including shadows, reflections, and textures — to maintain the context of the original image."
Technical limitations
DALL·E 2's language understanding has limits. It is sometimes unable to distinguish "A yellow book and a red vase" from "A red book and a yellow vase" or "A panda making latte art" from "Latte art of a panda". It generates images of "an astronaut riding a horse" when presented with the prompt "a horse riding an astronaut". It also fails to generate the correct images in a variety of circumstances. Requesting more than three objects, negation, numbers, and connected sentences may result in mistakes, and object features may appear on the wrong object. Additional limitations include handling text — which, even with legible lettering, almost invariably results in dream-like gibberish — and its limited capacity to address scientific information, such as astronomy or medical imagery.

Ethical concerns
DALL·E 2's reliance on public datasets influences its results and leads to algorithmic bias in some cases, such as generating higher numbers of men than women for requests that do not mention gender. In September 2022, OpenAI confirmed to The Verge that DALL·E invisibly inserts phrases into user prompts to address bias in results; for instance, "black man" and "Asian woman" are inserted into prompts that do not specify gender or race.
A concern about DALL·E 2 and similar image generation models is that they could be used to propagate deepfakes and other forms of misinformation. As an attempt to mitigate this, the software rejects prompts involving public figures and uploads containing human faces. Prompts containing potentially objectionable content are blocked, and uploaded images are analyzed to detect offensive material. A disadvantage of prompt-based filtering is that it is easy to bypass using alternative phrases that result in a similar output. For example, the word "blood" is filtered, but "ketchup" and "red liquid" are not.
Another concern about DALL·E 2 and similar models is that they could cause technological unemployment for artists, photographers, and graphic designers due to their accuracy and popularity. DALL·E 3 is designed to block users from generating art in the style of currently-living artists.
In 2023 Microsoft pitched the United States Department of Defense to use DALL·E models to train battlefield management system. In January 2024 OpenAI removed its blanket ban on military and warfare use from its usage policies.
Open-source implementations
Since OpenAI has not released source code for any of the three models, there have been several attempts to create open-source models offering similar capabilities. Released in 2022 on Hugging Face's Spaces platform, Craiyon (formerly DALL·E Mini until a name change was requested by OpenAI in June 2022) is an AI model based on the original DALL·E that was trained on unfiltered data from the Internet. It attracted substantial media attention in mid-2022, after its release due to its capacity for producing humorous imagery.
See also
- Artificial intelligence art
- DeepDream
- Imagen (Google Brain)
- Midjourney
- Stable Diffusion
- Prompt engineering
