
Analysis of algorithms facts for kids


In computer science, the analysis of algorithms is the process of finding the computational complexity of algorithms—the amount of time, storage, or other resources needed to execute them. Usually, this involves determining a function that relates the size of an algorithm's input to the number of steps it takes (its time complexity) or the number of storage locations it uses (its space complexity). An algorithm is said to be efficient when this function's values are small, or grow slowly compared to a growth in the size of the input. Different inputs of the same size may cause the algorithm to have different behavior, so best, worst and average case descriptions might all be of practical interest. When not otherwise specified, the function describing the performance of an algorithm is usually an upper bound, determined from the worst case inputs to the algorithm.
The term "analysis of algorithms" was coined by Donald Knuth. Algorithm analysis is an important part of a broader computational complexity theory, which provides theoretical estimates for the resources needed by any algorithm which solves a given computational problem. These estimates provide an insight into reasonable directions of search for efficient algorithms.
In theoretical analysis of algorithms it is common to estimate their complexity in the asymptotic sense, i.e., to estimate the complexity function for arbitrarily large input. Big O notation, Big-omega notation and Big-theta notation are used to this end. For instance, binary search is said to run in a number of steps proportional to the logarithm of the size n of the sorted list being searched, or in O(log n), colloquially "in logarithmic time". Usually asymptotic estimates are used because different implementations of the same algorithm may differ in efficiency. However the efficiencies of any two "reasonable" implementations of a given algorithm are related by a constant multiplicative factor called a hidden constant.
Exact (not asymptotic) measures of efficiency can sometimes be computed but they usually require certain assumptions concerning the particular implementation of the algorithm, called model of computation. A model of computation may be defined in terms of an abstract computer, e.g. Turing machine, and/or by postulating that certain operations are executed in unit time. For example, if the sorted list to which we apply binary search has n elements, and we can guarantee that each lookup of an element in the list can be done in unit time, then at most log2(n) + 1 time units are needed to return an answer.
Contents
Cost models
Time efficiency estimates depend on what we define to be a step. For the analysis to correspond usefully to the actual run-time, the time required to perform a step must be guaranteed to be bounded above by a constant. One must be careful here; for instance, some analyses count an addition of two numbers as one step. This assumption may not be warranted in certain contexts. For example, if the numbers involved in a computation may be arbitrarily large, the time required by a single addition can no longer be assumed to be constant.
Two cost models are generally used:
- the uniform cost model, also called uniform-cost measurement (and similar variations), assigns a constant cost to every machine operation, regardless of the size of the numbers involved
- the logarithmic cost model, also called logarithmic-cost measurement (and similar variations), assigns a cost to every machine operation proportional to the number of bits involved
The latter is more cumbersome to use, so it's only employed when necessary, for example in the analysis of arbitrary-precision arithmetic algorithms, like those used in cryptography.
A key point which is often overlooked is that published lower bounds for problems are often given for a model of computation that is more restricted than the set of operations that you could use in practice and therefore there are algorithms that are faster than what would naively be thought possible.
Relevance
Algorithm analysis is important in practice because the accidental or unintentional use of an inefficient algorithm can significantly impact system performance. In time-sensitive applications, an algorithm taking too long to run can render its results outdated or useless. An inefficient algorithm can also end up requiring an uneconomical amount of computing power or storage in order to run, again rendering it practically useless.
Constant factors
Analysis of algorithms typically focuses on the asymptotic performance, particularly at the elementary level, but in practical applications constant factors are important, and real-world data is in practice always limited in size. The limit is typically the size of addressable memory, so on 32-bit machines 232 = 4 GiB (greater if segmented memory is used) and on 64-bit machines 264 = 16 EiB. Thus given a limited size, an order of growth (time or space) can be replaced by a constant factor, and in this sense all practical algorithms are O(1) for a large enough constant, or for small enough data.
This interpretation is primarily useful for functions that grow extremely slowly: (binary) iterated logarithm (log*) is less than 5 for all practical data (265536 bits); (binary) log-log (log log n) is less than 6 for virtually all practical data (264 bits); and binary log (log n) is less than 64 for virtually all practical data (264 bits). An algorithm with non-constant complexity may nonetheless be more efficient than an algorithm with constant complexity on practical data if the overhead of the constant time algorithm results in a larger constant factor, e.g., one may have 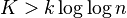 so long as
so long as 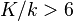 and
and 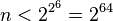 .
.
For large data linear or quadratic factors cannot be ignored, but for small data an asymptotically inefficient algorithm may be more efficient. This is particularly used in hybrid algorithms, like Timsort, which use an asymptotically efficient algorithm (here merge sort, with time complexity 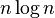 ), but switch to an asymptotically inefficient algorithm (here insertion sort, with time complexity
), but switch to an asymptotically inefficient algorithm (here insertion sort, with time complexity 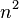 ) for small data, as the simpler algorithm is faster on small data.
) for small data, as the simpler algorithm is faster on small data.
See also
 In Spanish: Análisis de algoritmos para niños
In Spanish: Análisis de algoritmos para niños
